Recently, the Soul Zhang Lu team achieved a new technical milestone in real-time digital human generation. Its AI division (Soul AI Lab) publicly released the open-source model SoulX-LiveAct. Through structural optimizations to the autoregressive diffusion framework, this model elevates streaming generation from merely “functional” to “reliably stable over extended periods,” offering a more viable solution for deploying digital human technology in real-world applications.
Under previous technical approaches, AR diffusion possessed streaming generation capabilities but often struggled with two concurrent challenges in long-video scenarios: continuously growing GPU memory consumption and declining stability. SoulX-LiveAct addresses this by optimizing two critical components—condition propagation and historical memory management—enabling the model to retain essential historical context during prolonged operation while avoiding the performance overhead of infinitely expanding caches. This design equips the system with the architectural capacity to support longer, sustained generation while maintaining inference stability.
In terms of computational efficiency, SoulX-LiveAct achieves real-time streaming inference at 20 FPS with 512×512 resolution using only 2 H100/H200 GPUs. End-to-end latency is approximately 0.94 seconds, with per-frame computational cost held at 27.2 TFLOPs/frame. These results demonstrate that the model effectively controls hardware resource consumption while maintaining real-time performance, providing a practical cost reference for production deployment.
In extended generation scenarios, identity consistency and detail stability have always been key indicators of system reliability. To address common issues such as facial drift, clothing detail variation, and lip-sync misalignment, SoulX-LiveAct demonstrates robust stability across long time windows. Comparative experiments show that the model maintains consistent character identity features throughout continuous generation while preserving coherent rendering of accessories and texture details, thereby reducing quality fluctuations during prolonged operation.
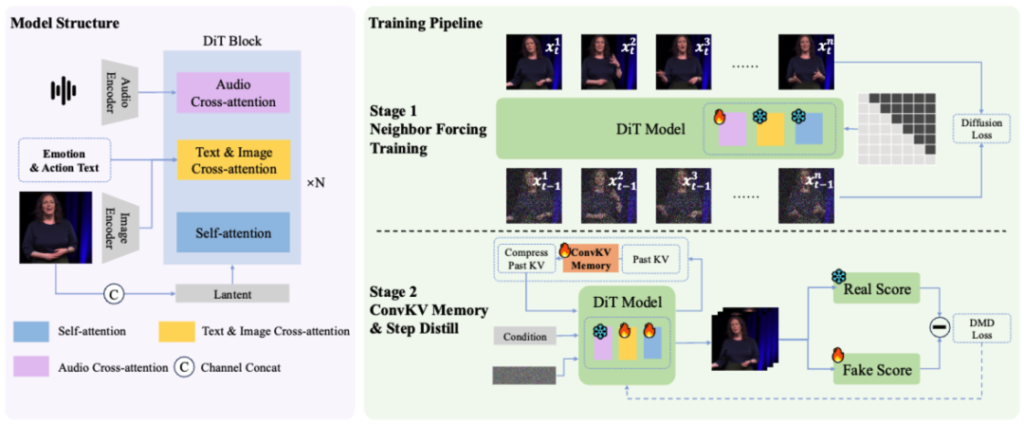
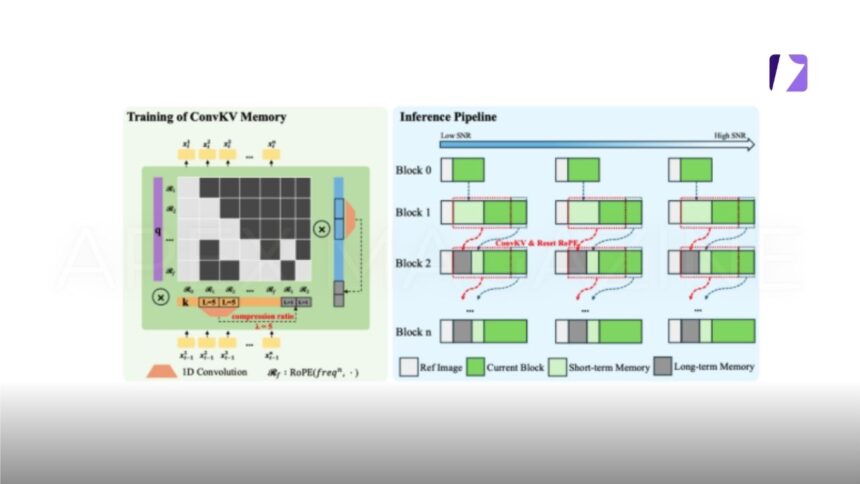
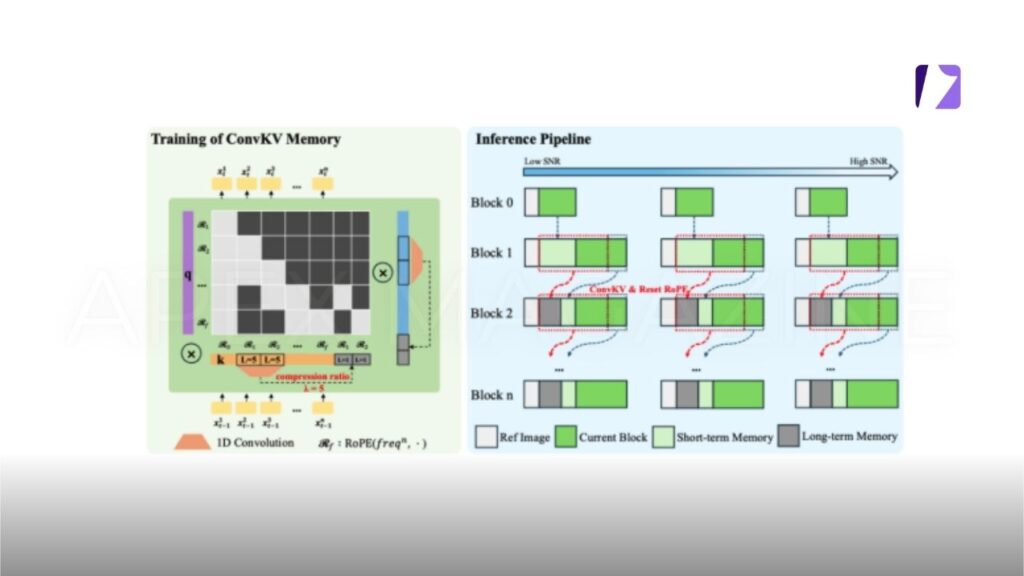
In terms of the technical approach, SoulX-LiveAct is built on the AR Diffusion paradigm and introduces two core mechanisms: Neighbor Forcing and ConvKV Memory. Neighbor Forcing propagates latent information from adjacent frames within the same diffusion step, ensuring that context and current predictions exist in a unified noise semantic space. This reduces distributional inconsistencies between training and inference phases. ConvKV Memory transforms the traditionally linearly growing KV cache into a “short-term precise + long-term compressed” structure. Achieving constant GPU memory inference through fixed-length memory representations while balancing local detail with global consistency. Additionally, a position encoding alignment mechanism enables the model to effectively avoid error accumulation caused by positional drift during long-sequence processing.
Regarding training strategy, SoulX-LiveAct organizes training samples by chunks. Exposing the model to continuous generation and error accumulation processes during training. Thereby improving its stability over extended operation. It also incorporates memory mechanisms consistent with those used during inference, allowing the model to learn to maintain identity and detail consistency even under compressed historical information, reducing the gap between training and real-world application.
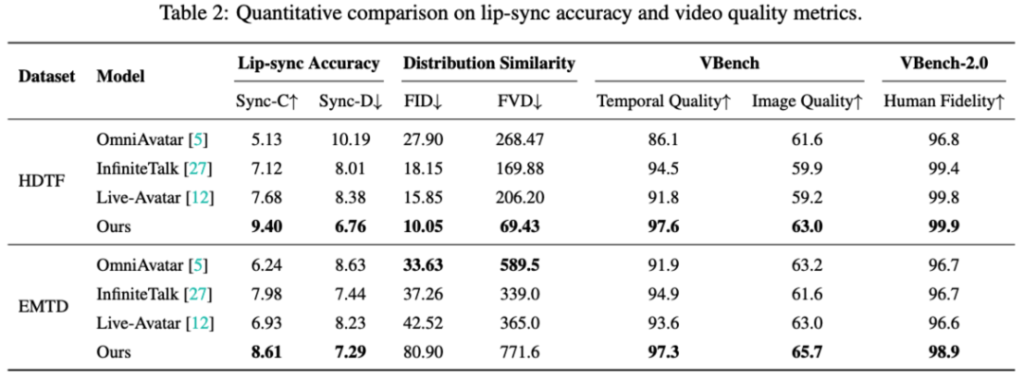
Across multiple benchmark evaluations, SoulX-LiveAct demonstrates well-balanced overall performance. On the HDTF dataset, it achieves a Sync-C of 9.40 and Sync-D of 6.76. Along with distribution similarity scores of 10.05 FID and 69.43 FVD. In VBench evaluations, Temporal Quality reaches 97.6 and Image Quality 63.0. VBench-2.0 Human Fidelity reaches 99.9. On the EMTD dataset, which includes full-body motion, the model maintains stable performance with Sync-C of 8.61 and Sync-D of 7.29. Achieving Temporal Quality and Image Quality scores of 97.3 and 65.7 respectively, with Human Fidelity at 98.9. These results reflect strong stability in lip-sync accuracy, motion performance, and overall consistency.
Based on the above performance, SoulX-LiveAct is well-suited for a variety of application scenarios demanding high real-time performance and stability. For instance, in digital human live streaming, AI-powered education, smart service terminals. And podcast recording, systems must maintain expressive consistency and natural interaction over extended periods. In open-world interactive environments, characters need to deliver sustained and stable voice and motion output. SoulX-LiveAct’s capabilities in full-body motion and long-duration inference make it well-positioned to support such complex application requirements.
By open-sourcing SoulX-LiveAct, the Soul Zhang Lu team further enriches. The technical landscape of real-time digital human generation, offering developers more adaptable solutions across varying hardware configurations and application needs. Its technical approach to balancing long-duration stability with real-time inference also provides. The industry with a new reference point for exploring continuous online interactive capabilities for digital humans.
Conclusion
SoulX-LiveAct represents a meaningful step forward in solving some of the most persistent challenges in long-duration video generation. By addressing GPU memory constraints and stability degradation through innovations like. Neighbor Forcing and ConvKV Memory, the model demonstrates that real-time, high-quality, and consistent. Digital human output is no longer a trade-off it is achievable at scale.
Its ability to maintain identity consistency, stabilize fine details, and deliver accurate lip-sync over extended. Sequences positions it as a strong foundation for next-generation interactive systems. From live streaming avatars to AI-driven education and immersive virtual environments. The model’s balance of efficiency and performance makes it highly practical for real-world deployment.
More broadly, the open-source release signals a shift toward more accessible and adaptable architectures in the digital human space. As developers build upon these innovations, SoulX-LiveAct could help define the next standard for continuous, real-time human-AI interaction.
VISIT MORE: APEX MAGAZINE







